- Blog/
Towards a Macroscope for UK Web History

Table of Contents
As published on the UK Web Archive blog.
This is the rough script of the demonstration I gave at IDCC15, with a few extra notes and details.
The UK Web Archive #
I work at the British Library as technical lead for the UK Web Archive, where we have been archiving thousands of UK web sites by permission since 2004. However, as of April 2013, we have been able to crawl the entire UK web domain under non-print Legal Deposit legislation, meaning that we now archive millions of sites every year. Furthermore, we also hold a copy of the JISC Historial Archive, which is a copy of every .uk resource from the Internet Archive collection up until the adoption of non-print Legal Deposit.
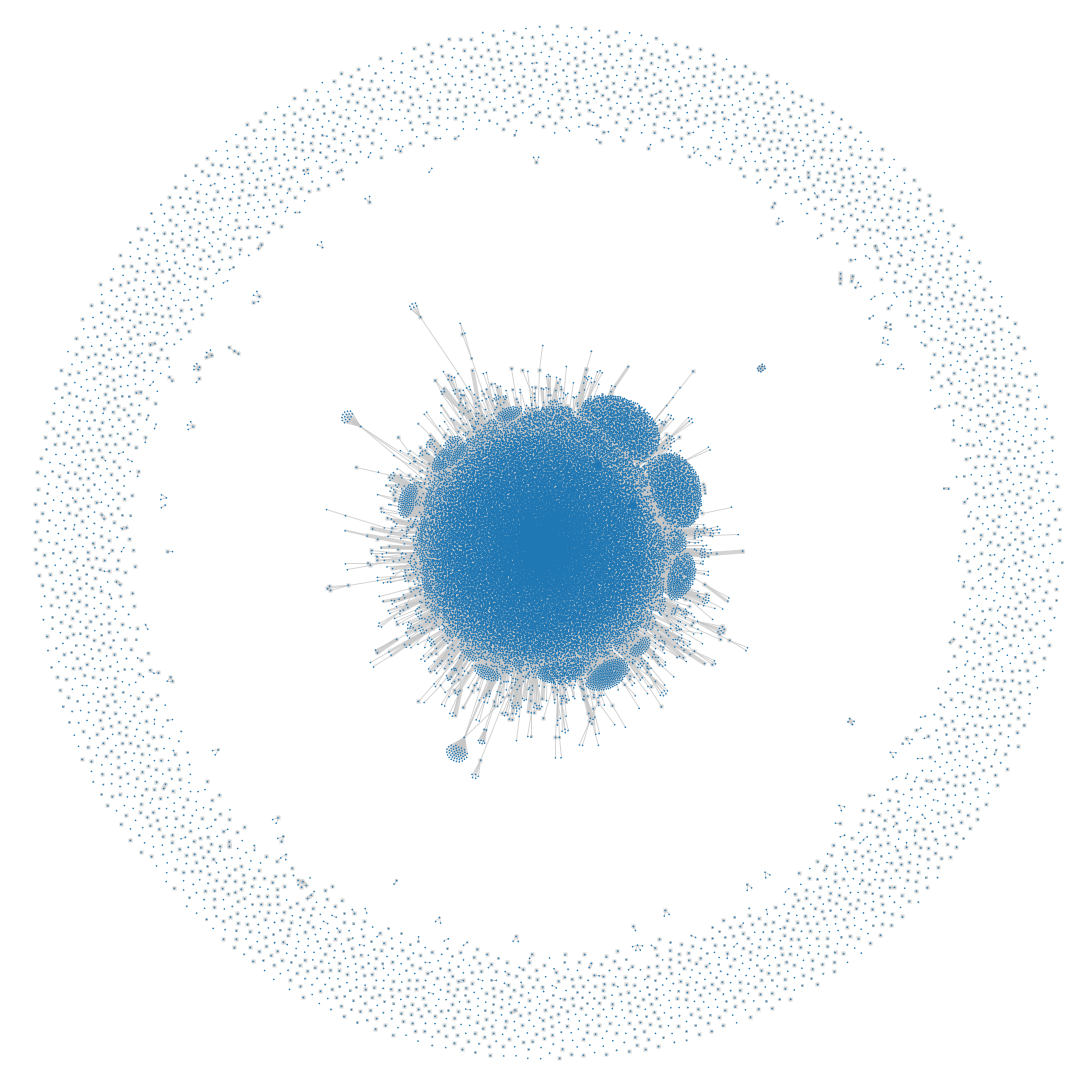
All together, our archives contain over six billion resources, over 100TB of compressed data, which means we have one big problem.
The Problem #

If our readers and researchers already know the URLs they are interested in, then it’s relatively easy to support. URL-based lookup of resources is necessary to enable us to ‘replay’ web pages, and so this is a feature of all web archives.
However, if the knowledge of the URL is lost, how can we help researchers find what they need?
The Solution? #
The obvious answer was to try and create something like a Google search - a full-text ‘historical’ search engine. However, building a search engine is a major undertaking and so, in order to ensure the development of such a system was relevant to our users, we decided to work closely with academic researchers who are interested in the modern web. First, this was funded by JISC, through the Analytical Access to the Domain Dark Archive project, which was later followed up by the currently ongoing AHRC-funded Big UK Domain Data for the Arts and Humanities project.
The process of building a historical search engine through these two projects has been a very challenging two main reasons. Firstly, the scale means we are at the limits of what many search technologies can support, and it has taken us a long time to learn how to effectively index billions of resources given the skills and hardware we have available.1
However, the bigger problem was the difference between the usual expectations for search and discovery that are baked into the tools, versus the actual needs of our researchers.
For example, what is the goal of a Google search? Well, the goal is to find the URL you want at the top of the list. “Just get me to the documents I need, as quickly as possible.”. That model of information retrieval is baked deep into the available features of search tools, like the assumption that word frequencies are crucial to relevant ranking.
But this is not what our researchers want.
The historians we consulted are generally not just looking for a few specific documents about a specific topic. They look to the web to see a refraction of wider society, and of the communities, groups and voices within them. Even when focussed on a relatively small subset of the whole, they still need to understand the position of that subset within the wider context of the whole dataset.
The Macroscope #
In 2011, Katy Börner advocated the implementation of “plug-and-play macroscopes] 1”, and the idea seems to have struck something of a chord within the digital humanities.2
“Macroscopes provide a ‘vision of the whole,’ helping us ‘synthesize’ the related elements and detect patterns, trends, and outliers while granting access to myriad details.” " Plug-and-Play Macroscopes" - Katy Börner (2011).
This approach neatly unifies the modern notion of ‘distant reading’ of texts with the more traditional ‘close reading’ approach, by encouraging individual items to be discovered via (or contra to) the prevailing trends, while also attempting to embed and present those individual resources in their broader context.
The Demonstration #
One of my research interests is around techonology evolution and adoption, so one of the searches I’ve done before is for CAPTCHA. Unlike current search engines, the default is to show you the very earliest records first. Here, the first crawled page is this BBC News article - Computer pioneer aids spam fight, crawled just two days after it was published. However, if we go back and look at the next hit, we see this Computing article which was actually published in December 2002. This illustrates how the dynamics of the crawler tend to favour popular sites, and so appear to skew the timeline of events. Something we will need to learn to correct for.
Faceted Search #
We can refine a bit more, just looking at 2003, and we see there are just 72 results. Digging deeper still, we can then just look at resources hosted on co.uk domains, to get an idea of which commercial organisations were talking about CAPTCHA in 2003. We can understand things a bit more if we then add the ‘Links Domains’ facet, which shows the domain names that these pages are linking to. Here, the website that first publicised CAPTCHAs is clearly visible, but if you then disable the 2003 filter, you can see that overall the sites that host CAPTCHAs dominate the picture in terms of links.
Corpus Building #
This illustrates the typical workflow followed by the researchers we collaborated with. Crucially, rather than relying on complex relevance ranking algorithms, we provide as many different facets and search options as we can, to help our historians ‘slice and dice’ the dataset in order to find sub-sets of the documents relevant to their particular interest.3
This is an important and indeed fairly traditional mode of engagement, usually ending in the ‘close reading’ of a farily small number of individual pages. However, it soon became clear that the researchers also need to understand something of the overall trends and biases of their corpora and of the wider context the corpora were drawn from.
Visualising Trends #
Within the faceted search, you can start to get a feel for this by searching for everything. You can quickly get an idea of the overall composition of the archive in terms of formats, domain names, links and years.
To make this kind of information more accessible, we have also added a visualisation interface for exploring overall trends within the dataset, broadly following the model of the Google Books NGram. This ‘distant reading’ mode gives our results a proper time-axis, like this one for ‘big data’.
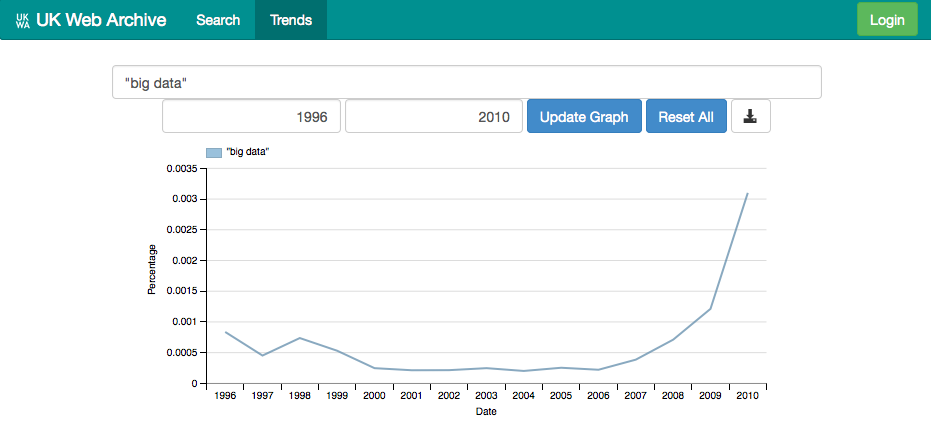
This graph is a fairly typical shape for many buzzwords within the UK web. A search for iPhone quickly illustrates the rapid growth in importance of Apple device.
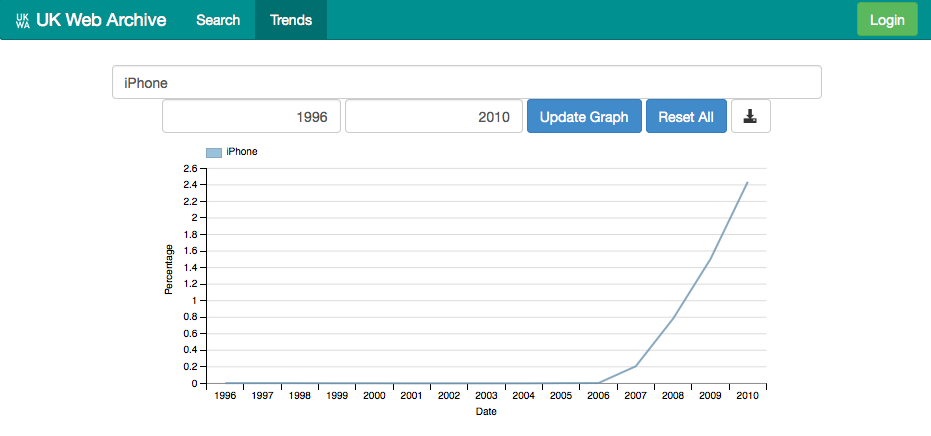
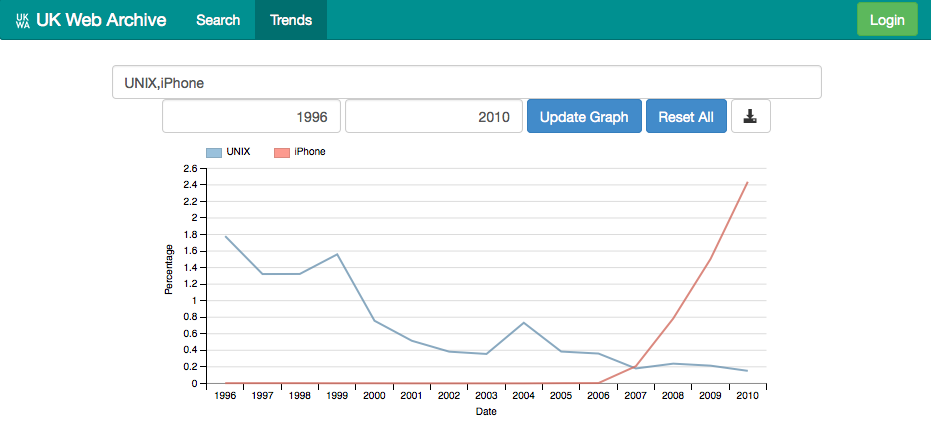
Then, by adding another search term ( iPhone,UNIX), we can quickly contrast that with a much older but less fashionable technology.
Furthermore, if you know the right incantations, any of the search fields known to the system can be used in the trends interface. For example, you can construct a search that compares the percentage of resources on ac.uk versus co.uk over time.
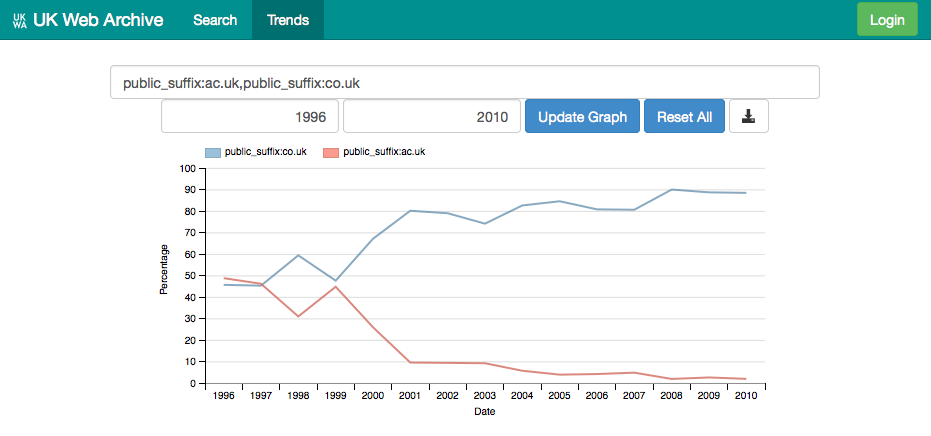
So, while in absolute terms, both ac.uk and co.uk have grown significantly since 1996, the rate of growth of co.uk far outstrips that of ac.uk. This illustrates the kinds of overall trends that can appear in a large-scale web crawl, the presence of which must be taken into account when interpreting trends relating to commercial or academic hosts.
Understanding Trends #
Interesting and useful though this may be, it is still a rather poor Macroscope. Specifically, the composition of voices underneath these trends remains unclear.
For example, if you look at the iPhone curve, and switch to a logarithmic scale (by clicking the vertical axis label), you see a strange dip ahead of the growth curve.
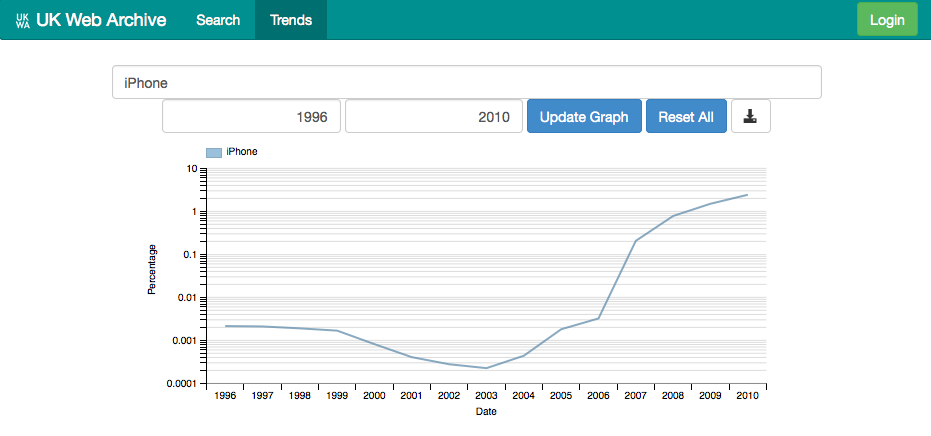
What’s going on?
Well, by clicking on a data point, the system attemps to bridge the gap between the trend and the underlying data by fetching a fairly large randomly-selected sample of the ‘hits’ that contribute to that point on the curve. This provides a very fast and natural way to evaluate the trends and understand what’s going on underneath them.
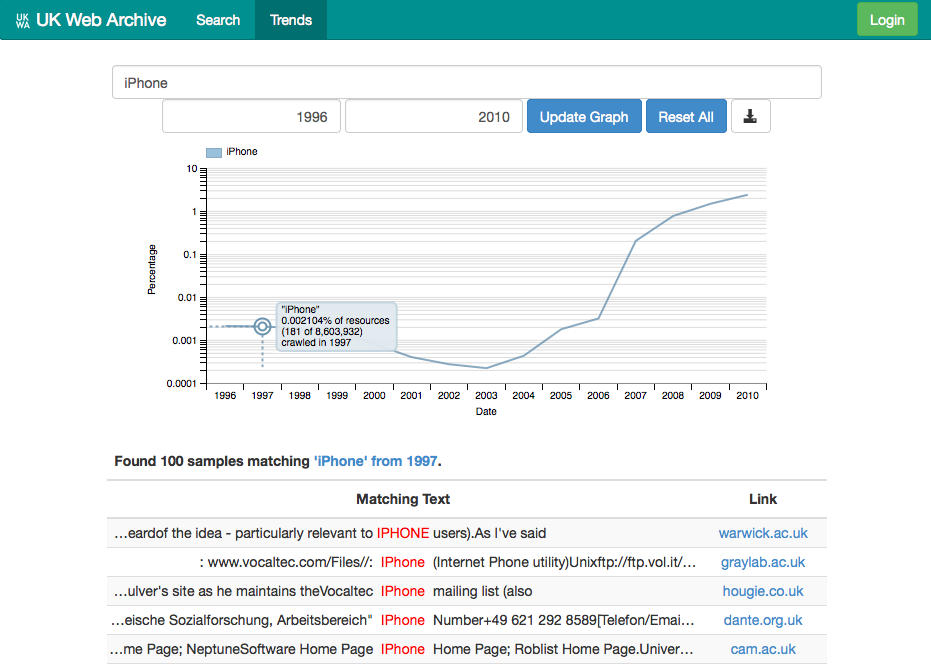
From this I was able to learn that in the late nineties there was a Internet Phone called the IPhone, and that this was still in some use as the iPhone hype began.
Similarly, if you search for something like terrorism OR terrorist, you can see peaks associated with major events, and start to dig into them.
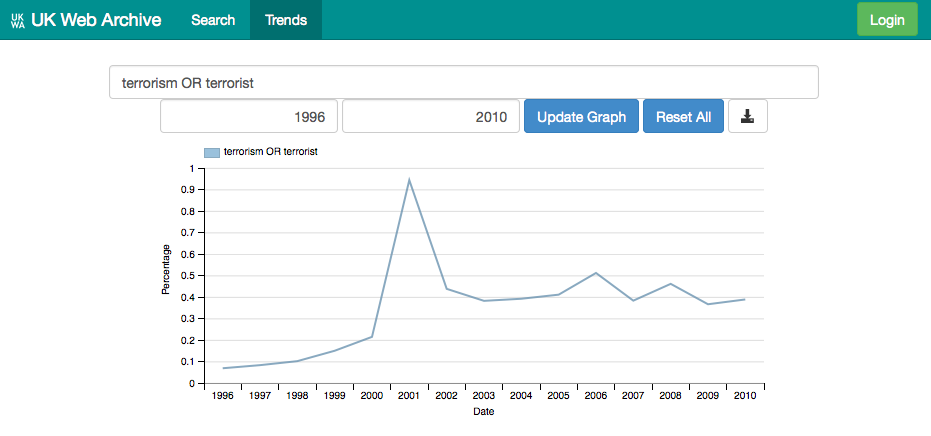
In particular, this curve shows that the occurance of the words terrorism or terrorist not only peaked during 2001, but that the fraction of the web that discusses terrorism has been greater ever since.
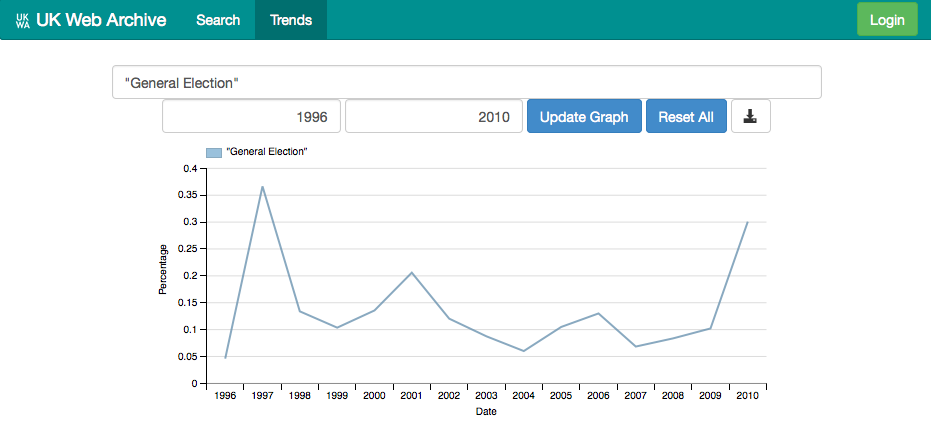
The same approach can be used to study periodic events, e.g. “General Election”.
Searching for Genome provides another interesting example. At first, I expected this peak to be related to news about the human genome sequencing project, but by digging into it, we can see that the truth is more complicated than that. A significant fraction of these hist appear to come from the Sanger Institute itself, but more associated with the development of the institute’s website rather than a specific experimental milestone.
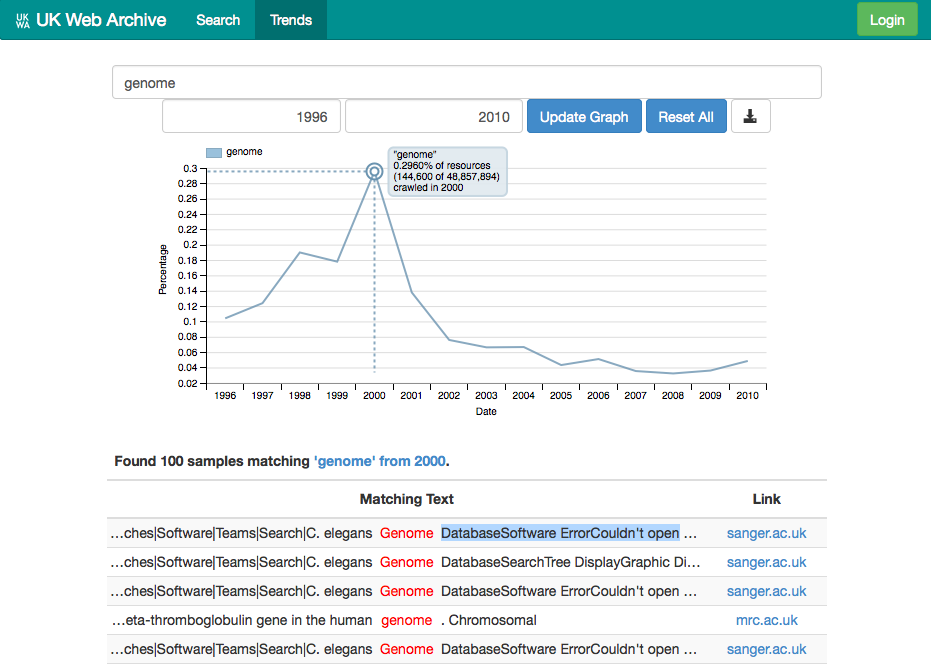
In this way, by providing samples and links back to full search results, we make it much easier for a researcher’s assumptions about the data to be tested. It also helps make unexpected biases and flaws in the dataset much more apparent.
Although this is a very early prototype, I hope you can see the potential that this kind of ‘Macroscope’ in helping understand large and complex collections like web archives.
The Future #
There are two main challenges to this work, going ahead. The first is scale and sustainability - our collection is growing very rapidly, and it is not yet clear whether the level of sophistication I’ve demonstrated today can be maintained over time.
The second challenge is to provide the features and usability that make this a compelling, powerful and useful service. Our partnership with historians has been fruitful, but their feedback also made it clear that significant modifications are requried to improve the quality of the search results and the utility of the system.
It is therefore very important for us to be able to show that this is valuable to researchers, in order to justify future development as a core part of what the web archive does, and so we’d be very interested in hearing about any project that can benefit from our historical search engine.
Thank you.
Appendix #
Other interesting searches:
- terrorism OR terrorist, iraq, showing how the peak in mentions of Iraq lags and echos the mentions of terrorism.
- Olympics OR Olympic, with the repeating peaks visible, but also hinting at the build up the the London Olympics.
- “john major”,“tony blair”,“michael howard”,“gordon brown”,“david cameron”, showing how peaks in mentions of party leaders are correlated with general elections, and with which part won.
Even now, as you’ll see, our search response times are fairly slow (at least compared to something like a Google search) and, more problematically, the search service can be a little flaky under load. Which you may also soon see! ↩︎
In particular,the way Tim Hitchcock presented the Macroscope at a recent presentation called Big Data, Small Data and Meaning, here at the British Library Labs, has influenced how we frame our approach to this problem. ↩︎
Users can also save their queries, and to create corpora based on those queries which can then be fine-tuned, weeding out the irrelevant hits. These corpora can be annotated and further queries can be restricted to those subsets alone. ↩︎